Pattern: Reflection¶
Motivation¶
Writers revise their drafts, checking for clarity and flow. Scientists review their experiments before publication. Students review their answers before submitting. Reflection is our built-in quality control: stepping back, evaluating our work, identifying improvements, and refining until it meets our standards. The Reflection pattern gives agents this same ability: to review, critique, and improve their own outputs through iterative self-evaluation.
Pattern Overview¶
Problem¶
Even with sophisticated workflows using chaining, routing, and parallelization, an agent's initial output might not be optimal, accurate, or complete. Tasks with complex requirements, multiple nuanced constraints, or high accuracy demands often cannot be met in a single pass. Without a mechanism for self-correction and iterative refinement, agents remain single-pass executors that cannot improve their own outputs, leading to suboptimal results that fail to meet complex requirements.
Solution¶
Reflection introduces a feedback loop where the agent doesn't just produce an output; it examines that output, identifies potential issues or areas for improvement, and uses those insights to generate a better version or modify its future actions. The process involves execution (generating initial output), evaluation/critique (analyzing for accuracy, coherence, completeness, or adherence to instructions), reflection/refinement (determining how to improve), and iteration (repeating until satisfactory or a stopping condition is met).
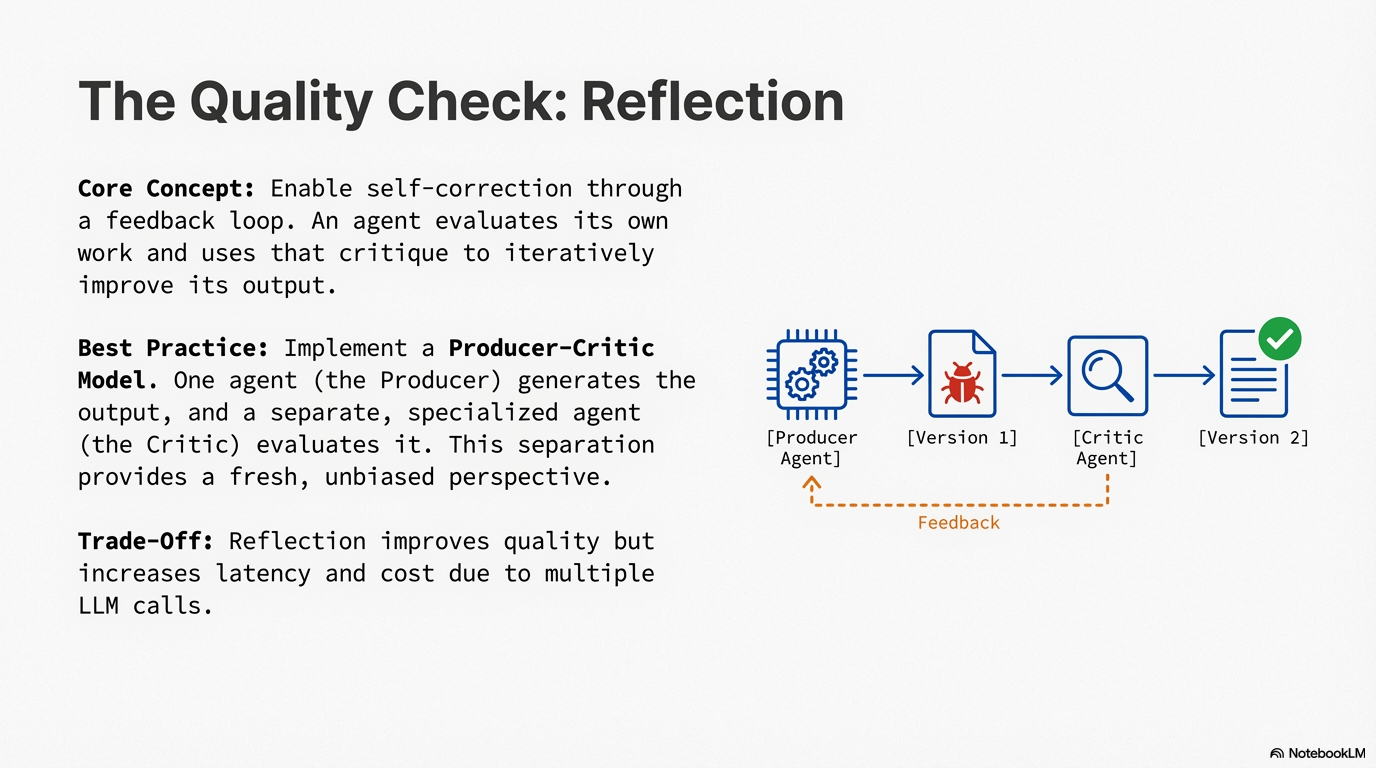
A key and highly effective implementation separates the process into two distinct roles: a Producer and a Critic (Generator-Critic model). While a single agent can perform self-reflection, using two specialized agents (or two separate LLM calls with distinct system prompts) often yields more robust and unbiased results. The Producer focuses on generating content, while the Critic evaluates it with a fresh perspective, dedicated entirely to finding errors and areas for improvement. This separation prevents cognitive bias and enables objective evaluation, transforming agents from single-pass executors into systems capable of iterative self-improvement.
Key Concepts¶
- Feedback Loop: Reflection introduces a cyclical process of generation, evaluation, and refinement rather than linear execution.
- Producer-Critic Model: Separating generation and evaluation into distinct agents or roles prevents cognitive bias and improves objectivity.
- Iterative Refinement: The pattern enables multiple passes of improvement, with each iteration building on previous critiques.
- Quality vs. Speed Trade-off: Reflection improves quality but increases latency and cost due to multiple LLM calls.
How It Works¶
Reflection works through a structured feedback cycle. First, a Producer agent generates initial output based on the task. Then, a Critic agent (or the same agent in a different role) evaluates this output against specific criteria—factual accuracy, code quality, stylistic requirements, completeness, or adherence to instructions. The Critic provides structured feedback identifying flaws and suggesting improvements.
This feedback is then passed back to the Producer, which uses it to generate a refined version. The cycle can repeat until the Critic determines the output is satisfactory (often signaled by a "PERFECT" or "SATISFACTORY" status) or a maximum iteration limit is reached. The separation of Producer and Critic roles is powerful because it prevents the cognitive bias of an agent reviewing its own work—the Critic approaches with a fresh perspective.
Implementing reflection requires structuring workflows to include these feedback loops, often using state management and conditional transitions based on evaluation results. Frameworks like LangGraph support iterative loops natively, while LangChain can implement single reflection steps, and Google ADK facilitates reflection through sequential workflows where one agent's output is critiqued by another.
When to Use This Pattern¶
✅ Use this pattern when:¶
- Quality is paramount: The task requires high-quality, accurate, or polished outputs where errors are costly.
- Complex requirements: The task has multiple, nuanced requirements that are difficult to meet in a single pass.
- Iterative improvement is possible: The output can be refined based on feedback without starting completely over.
- Specialized evaluation needed: The task benefits from objective, specialized critique (code review, fact-checking, style analysis).
- Error correction is critical: The domain requires high accuracy and the ability to catch and fix errors.
❌ Avoid this pattern when:¶
- Speed is critical: Real-time or low-latency requirements make iterative refinement impractical.
- Cost constraints: Budget limitations make multiple LLM calls per task prohibitive.
- Simple tasks: The task is straightforward enough that a single pass produces adequate results.
- Non-refinable outputs: The output type doesn't benefit from iterative improvement (e.g., simple lookups).
- Context window limits: The iterative process would exceed context window capacity.
Decision Guidelines¶
Use reflection when the quality improvement justifies the added cost and latency. Consider: the complexity of requirements (more complex = more benefit), the cost of errors (high-stakes = worth the cost), and the refinability of the output (some outputs improve with iteration, others don't). The Producer-Critic model is particularly valuable when objectivity is important or when specialized evaluation expertise is needed. Be mindful of iteration limits to prevent infinite loops and manage costs.
Practical Applications & Use Cases¶
Reflection is valuable in scenarios where output quality, accuracy, or adherence to complex constraints is critical.
- Creative Writing: Refine generated text, stories, or marketing copy through iterative critique and revision cycles.
- Code Generation: Write code, identify errors through testing or static analysis, and refine based on findings.
- Complex Problem Solving: Evaluate intermediate steps in multi-step reasoning, backtracking when needed.
- Summarization: Refine summaries for accuracy and completeness by comparing against source material.
- Planning: Evaluate proposed plans for feasibility and effectiveness, revising based on critique.
Implementation¶
Prerequisites:
Basic Example
```python from langchain_openai import ChatOpenAI from langchain_core.messages import SystemMessage, HumanMessage
llm = ChatOpenAI(model="gpt-4o", temperature=0.1)
def reflect_and_refine(task: str, max_iterations: int = 3): """Simple reflection loop for code generation."""
current_output = ""
message_history = [HumanMessage(content=task)]
for i in range(max_iterations):
# Producer: Generate or refine
if i == 0:
response = llm.invoke(message_history)
current_output = response.content
else:
message_history.append(HumanMessage(
content="Please refine based on the critique."
))
response = llm.invoke(message_history)
current_output = response.content
message_history.append(response)
# Critic: Evaluate
critique_prompt = [
SystemMessage(content="""You are a senior code reviewer.
Evaluate the code. If perfect, say 'PERFECT'.
Otherwise, provide critiques."""),
HumanMessage(content=f"Task: {task}\n\nCode: {current_output}")
]
critique = llm.invoke(critique_prompt).content
if "PERFECT" in critique:
break
message_history.append(HumanMessage(
content=f"Critique: {critique}"
))
return current_output
Use¶
code = reflect_and_refine("Write a Python function to calculate factorial") print(code) ```
Explanation: This example demonstrates a basic reflection loop. The Producer generates code, the Critic evaluates it, and the Producer refines based on feedback. The loop continues until the Critic approves or max iterations are reached. This shows the core feedback mechanism of the Reflection pattern.
Advanced Example
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage
from langchain_core.output_parsers import JsonOutputParser
llm = ChatOpenAI(model="gpt-4o", temperature=0.1)
def produce(task: str) -> str:
response = llm.invoke([HumanMessage(content=task)])
return response.content
def critique(output: str, criteria: str) -> dict:
prompt = [
SystemMessage(content=f"""Evaluate. Return JSON: {{"score": float, "feedback": str, "status": "PASS|FAIL"}}
Criteria: {criteria}"""),
HumanMessage(content=output)
]
chain = prompt | llm | JsonOutputParser()
return chain.invoke({})
def reflect(task: str, max_iterations: int = 3) -> str:
output = produce(task)
for i in range(max_iterations):
eval_result = critique(output, "quality, accuracy")
if eval_result.get("status") == "PASS":
break
output = llm.invoke([
HumanMessage(content=task),
HumanMessage(content=f"Previous: {output}"),
HumanMessage(content=f"Feedback: {eval_result['feedback']}\nRefine:")
]).content
return output
result = reflect("Write a blog post about AI agents")
print(result)
Explanation: This advanced example implements a full ReflectionAgent class with structured evaluation, quality scoring, and detailed iteration tracking. The Critic provides structured JSON feedback with scores, enabling more sophisticated stopping conditions and quality monitoring. This demonstrates production-ready reflection with quality thresholds and comprehensive iteration history.
Framework-Specific Examples¶
Langgraph
from langgraph.graph import StateGraph, END
from langchain_openai import ChatOpenAI
from typing import TypedDict
llm = ChatOpenAI(temperature=0.1)
class ReflectionState(TypedDict):
task: str
output: str
critique: str
iteration: int
def produce_node(state: ReflectionState) -> ReflectionState:
output = llm.invoke(f"Task: {state['task']}").content
return {**state, "output": output}
def critique_node(state: ReflectionState) -> ReflectionState:
critique = llm.invoke(f"Evaluate. If perfect say 'PERFECT': {state['output']}").content
return {**state, "critique": critique}
def should_continue(state: ReflectionState) -> str:
if "PERFECT" in state["critique"] or state["iteration"] >= 3:
return "end"
return "refine"
def refine_node(state: ReflectionState) -> ReflectionState:
output = llm.invoke(f"Refine: {state['critique']}\n{state['output']}").content
return {**state, "output": output, "iteration": state["iteration"] + 1}
graph = StateGraph(ReflectionState)
graph.add_node("produce", produce_node)
graph.add_node("critique", critique_node)
graph.add_node("refine", refine_node)
graph.set_entry_point("produce")
graph.add_edge("produce", "critique")
graph.add_conditional_edges("critique", should_continue, {"end": END, "refine": "refine"})
graph.add_edge("refine", "produce")
result = graph.invoke({"task": "Write a function", "output": "", "critique": "", "iteration": 0})
print(result["output"])
Google ADK
from google.adk.agents import LlmAgent, SequentialAgent
# Producer agent
generator = LlmAgent(
name="DraftWriter",
model="gemini-2.0-flash",
instruction="Write a short paragraph about the subject.",
output_key="draft_text"
)
# Critic agent
reviewer = LlmAgent(
name="FactChecker",
model="gemini-2.0-flash",
instruction="""Review the text in 'draft_text'.
Return JSON: {"status": "ACCURATE"|"INACCURATE", "reasoning": str}""",
output_key="review_output"
)
# Pattern: Reflection pipeline
review_pipeline = SequentialAgent(
name="WriteAndReview",
sub_agents=[generator, reviewer]
)
Key Takeaways¶
- Core Concept: Reflection enables iterative self-correction through feedback loops of generation, evaluation, and refinement.
- Best Practice: Use a Producer-Critic model with separate agents or roles for more objective, unbiased evaluation.
- Common Pitfall: Reflection increases cost and latency; set iteration limits and quality thresholds to manage this.
- Performance Note: Each iteration requires additional LLM calls, increasing token usage and latency, but significantly improving output quality.
Related Patterns¶
This pattern works well with: - Goal Setting and Monitoring - Goals provide benchmarks for evaluation, monitoring tracks progress - Memory Management - Conversation history enables cumulative learning from past critiques - Planning - Reflection can evaluate and refine plans before execution
This pattern is often combined with: - Exception Handling - Reflection can identify and correct errors before they cause failures - Evaluation and Monitoring - Structured evaluation metrics guide the reflection process

References
- LangGraph Iterative Workflows: https://langchain-ai.github.io/langgraph/how-tos/iterative/
- Google ADK Sequential Agents: https://google.github.io/adk-docs/agents/sequential/
- Self-Consistency and Chain-of-Thought: https://arxiv.org/abs/2203.11171