Pattern: Prompt Chaining¶
Motivation¶
When cooking a complex recipe, you don't try to do everything at once. You first gather ingredients, then prep them, then cook in stages, using the output of each step as input for the next. Similarly, when assembling furniture, you follow numbered steps sequentially, where each step builds on the previous one. Prompt chaining mirrors this natural human approach: breaking complex tasks into manageable, sequential steps where each stage produces results that inform the next.
"Graph structure is where reliability comes from." — LangGraph
Pattern Overview¶
Problem¶
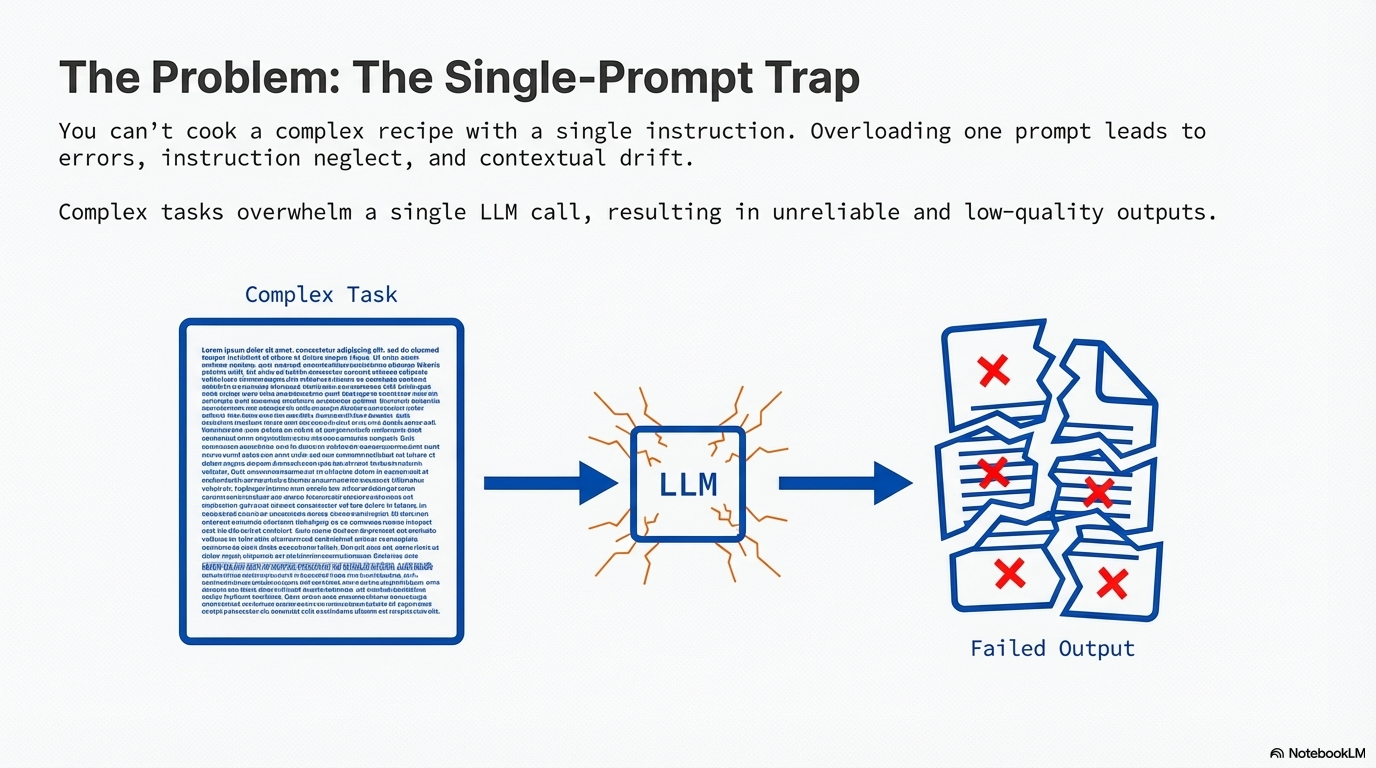
Complex tasks often overwhelm LLMs when handled within a single prompt, leading to instruction neglect, contextual drift, error propagation, and hallucinations. When a task is too complex for a single prompt, involves multiple distinct processing stages, requires interaction with external tools between steps, or needs to perform multi-step reasoning with a predetermined sequence, a single-prompt approach fails to provide the reliability, control, and modularity needed for robust execution.
Solution¶
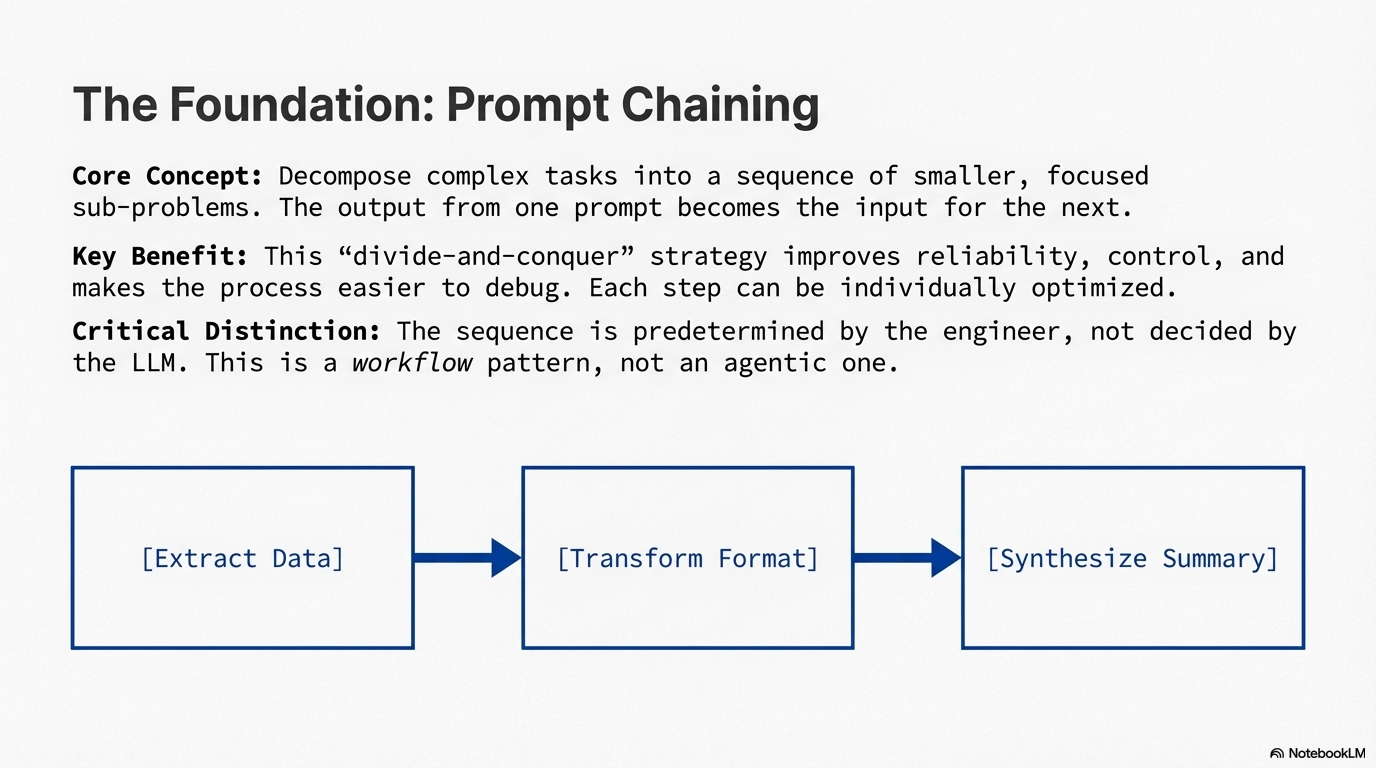
Prompt Chaining, sometimes referred to as the Pipeline Pattern, is a technique for handling intricate tasks with LLMs by breaking down complex problems into a sequence of smaller, manageable sub-problems. Each sub-problem is addressed through a specifically designed prompt, and the output from one prompt is strategically fed as input into the subsequent prompt in the chain. This sequential processing technique inherently introduces modularity and clarity into the interaction with LLMs.
By decomposing a complex task, it becomes easier to understand and debug each individual step, making the overall process more robust and interpretable. Each step in the chain can be meticulously crafted and optimized to focus on a specific aspect of the larger problem, leading to more accurate and focused outputs. The output of one step acting as the input for the next establishes a dependency chain, where the context and results of previous operations guide the subsequent processing. This allows the LLM to build on its previous work, refine its understanding, and progressively move closer to the desired solution. This modular, divide-and-conquer strategy makes the process more manageable, easier to debug, and allows for the integration of external tools or structured data formats between steps.
Key Distinction from Agents: In prompt chaining, the engineer hardcodes the sequence. The LLM never decides what to do next—it only processes the input according to the predefined prompt. If the "if/else" logic is in your Python code, it's a workflow using prompt chaining. If the "if/else" logic is generated by the LLM, it's an agent.
Key Concepts¶
- Sequential Decomposition: Breaking complex tasks into a sequence of smaller, focused sub-tasks that build upon each other.
- Output-to-Input Chaining: The output from one prompt step becomes the input for the next, creating a logical workflow progression.
- Structured Output: Using formats like JSON or XML between steps to ensure data integrity and machine-readability.
- Modular Design: Each step in the chain can be independently optimized, tested, and debugged.
- Tool Integration: External tools, APIs, or databases can be integrated at any step in the chain.
- Workflow Pattern: This is a workflow pattern, not an agentic pattern—the sequence is predetermined by the engineer.
How It Works¶
Prompt chaining operates through a sequential workflow where each step processes input and produces output that feeds into the next step. First, the complex task is decomposed into logical sub-tasks, each with a specific purpose (e.g., extraction, transformation, synthesis). Second, each sub-task is assigned a focused prompt that instructs the LLM to perform that specific operation. Third, the output from each step is captured, potentially validated or transformed, and passed as input to the next prompt. Fourth, structured output formats (JSON, XML) are used between steps to ensure data integrity and prevent parsing errors. Finally, the chain executes sequentially, with each step building upon the results of previous steps until the final output is produced.
When to Use This Pattern¶
✅ Use this pattern when:¶
- Complex multi-step tasks: Tasks that require multiple distinct processing stages that build upon each other.
- Single prompt is insufficient: The task is too complex or has too many constraints to handle reliably in a single prompt.
- Tool integration needed: You need to interact with external tools, APIs, or databases between processing steps.
- Structured data transformation: Converting unstructured data through multiple transformation stages (e.g., extract → normalize → format).
- Sequential reasoning required: Tasks that require multi-step reasoning with a predetermined sequence.
- Debugging and reliability: You need granular control and the ability to debug individual steps in a complex process.
❌ Avoid this pattern when:¶
- Simple single-step tasks: Tasks that can be reliably completed with a single, well-crafted prompt.
- Dynamic decision-making needed: When the sequence of steps should be determined at runtime by the LLM (use agents instead).
- Parallel processing possible: When sub-tasks are independent and can be executed in parallel (use parallelization pattern instead).
- Low-latency requirements: When the overhead of multiple sequential LLM calls is prohibitive.
- Minimal complexity: When the added complexity of chaining doesn't provide sufficient benefit over a single prompt.
Decision Guidelines¶
Choose prompt chaining when the benefits of modularity, reliability, and control outweigh the added complexity and latency of multiple sequential calls. Consider the task complexity: if a single prompt consistently fails or produces unreliable results, chaining is likely beneficial. Consider the processing stages: if the task naturally decomposes into distinct stages (extract → transform → synthesize), chaining is appropriate. Consider tool integration: if you need to use external tools between steps, chaining provides a natural structure. However, if the sequence should be dynamic or determined by the LLM, consider using an agentic pattern instead.
"You don't prompt a model; you stage a cognitive environment for it." — Anthropic
Practical Applications & Use Cases¶
Prompt chaining is a versatile pattern applicable in a wide range of scenarios when building LLM-powered workflows. Common applications include information processing, complex query answering, and content generation.
- Information Processing Workflows: Processing raw information through multiple transformations (extract text → summarize → extract entities → query database → generate report).
- Complex Query Answering: Answering questions that require multiple steps of reasoning or information retrieval (identify sub-questions → research each → synthesize answer).
- Data Extraction and Transformation: Converting unstructured text into structured formats through iterative refinement (extract fields → validate → refine missing fields → output structured data).
- Content Generation Workflows: Composing complex content through distinct phases (generate ideas → create outline → draft sections → review and refine).
- Conversational Agents with State: Maintaining conversational continuity by incorporating previous context into each turn (process utterance → update state → generate response).
- Code Generation and Refinement: Generating functional code through multiple stages (understand request → generate outline → write code → identify errors → refine → add documentation).
- Multimodal and Multi-Step Reasoning: Analyzing datasets with diverse modalities through sequential processing (extract text → link with labels → interpret with tables).
Implementation¶
Prerequisites:
Note: langchain-openai can be substituted with the appropriate package for a different model provider (e.g., langchain-google-genai for Gemini).
Basic Example
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
llm = ChatOpenAI(temperature=0)
prompt_extract = ChatPromptTemplate.from_template(
"Extract the technical specifications from: {text_input}"
)
prompt_transform = ChatPromptTemplate.from_template(
"Transform into JSON with 'cpu', 'memory', 'storage': {specifications}"
)
extraction_chain = prompt_extract | llm | StrOutputParser()
full_chain = {"specifications": extraction_chain} | prompt_transform | llm | StrOutputParser()
result = full_chain.invoke({"text_input": "3.5 GHz CPU, 16GB RAM, 1TB SSD"})
print(result)
Explanation: This example demonstrates a two-step prompt chain that functions as a data processing pipeline. The initial stage extracts technical specifications from unstructured text, and the subsequent stage transforms the extracted output into a structured JSON format. The LangChain Expression Language (LCEL) elegantly chains these prompts together, with the output of the first chain automatically feeding into the second prompt.
Advanced Example: Multi-Step Workflow
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser, JsonOutputParser
from langchain_core.pydantic_v1 import BaseModel, Field
from typing import List
llm = ChatOpenAI(temperature=0)
class Trend(BaseModel):
trend_name: str = Field(description="Name of the trend")
supporting_data: str = Field(description="Data point supporting the trend")
class TrendsResponse(BaseModel):
trends: List[Trend]
summarize_chain = ChatPromptTemplate.from_template(
"Summarize key findings: {report_text}"
) | llm | StrOutputParser()
extract_chain = ChatPromptTemplate.from_template(
"Extract top 3 trends from: {summary}"
) | llm | JsonOutputParser(pydantic_object=TrendsResponse)
email_chain = ChatPromptTemplate.from_template(
"Draft email about: {trends_json}"
) | llm | StrOutputParser()
summary = summarize_chain.invoke({"report_text": "Market research shows 73% prefer personalized experiences..."})
trends = extract_chain.invoke({"summary": summary})
email = email_chain.invoke({"trends_json": str(trends)})
print(email)
Explanation: This advanced example demonstrates a three-step workflow for processing a market research report. The chain summarizes the report, extracts trends with structured output, and generates an email. Using Pydantic models for structured output ensures data integrity between steps, and each step can be independently tested and optimized.
Framework-Specific Examples¶
Langgraph
from langgraph.graph import StateGraph, END
from langchain_openai import ChatOpenAI
from typing import TypedDict
llm = ChatOpenAI(temperature=0)
class ChainState(TypedDict):
input_text: str
extracted: str
transformed: str
def extract_step(state: ChainState) -> ChainState:
result = llm.invoke(f"Extract specs from: {state['input_text']}")
return {**state, "extracted": result.content}
def transform_step(state: ChainState) -> ChainState:
result = llm.invoke(f"Transform to JSON: {state['extracted']}")
return {**state, "transformed": result.content}
graph = StateGraph(ChainState)
graph.add_node("extract", extract_step)
graph.add_node("transform", transform_step)
graph.set_entry_point("extract")
graph.add_edge("extract", "transform")
graph.add_edge("transform", END)
result = graph.invoke({"input_text": "3.5GHz CPU, 16GB RAM, 1TB SSD"})
print(result["transformed"])
Google ADK
Key Takeaways¶
- Core Concept: Prompt chaining breaks down complex tasks into a sequence of smaller, focused steps, improving reliability and manageability.
- Best Practice: Use structured output formats (JSON, XML) between steps to ensure data integrity and prevent parsing errors.
- Common Pitfall: Over-chaining can add unnecessary latency; only chain when the complexity justifies multiple steps.
- Performance Note: Each step in the chain requires an LLM call, increasing latency and cost; consider caching intermediate results when possible.
- Key Distinction: This is a workflow pattern, not an agentic pattern—the sequence is predetermined by the engineer, not dynamically decided by the LLM.
Related Patterns¶
This pattern works well with:
- Parallelization - Independent sub-tasks can be processed in parallel before chaining dependent steps
- Routing - Chains can branch to different paths based on conditions
- Tool Use - External tools can be integrated at any step in the chain
This pattern is often combined with:
- Structured Output - Using JSON/XML formats between steps ensures data integrity
- Context Engineering - Each step benefits from well-engineered context
- Reflection - Chains can include reflection steps to review and refine outputs
References
- LangChain Documentation on LCEL: https://python.langchain.com/v0.2/docs/core_modules/expression_language/
- LangGraph Documentation: https://langchain-ai.github.io/langgraph/
- Prompt Engineering Guide - Chaining Prompts: https://www.promptingguide.ai/techniques/chaining
- OpenAI API Documentation: https://platform.openai.com/docs/guides/gpt/prompting
- Crew AI Documentation: https://docs.crewai.com/
- Google AI for Developers: https://cloud.google.com/discover/what-is-prompt-engineering?hl=en
- Vertex Prompt Optimizer: https://cloud.google.com/vertex-ai/generative-ai/docs/learn/prompts/prompt-optimizer