Pattern: Parallelization¶
Motivation¶
When hosting a dinner party, you don't cook dishes one at a time. You chop vegetables while the pasta boils, set the table while the sauce simmers, and delegate tasks to others. In a team project, people work on different parts simultaneously. Parallelization in agents mirrors this: executing independent operations concurrently to save time and increase efficiency, just as humans naturally multitask and coordinate parallel efforts.
Pattern Overview¶
Problem¶
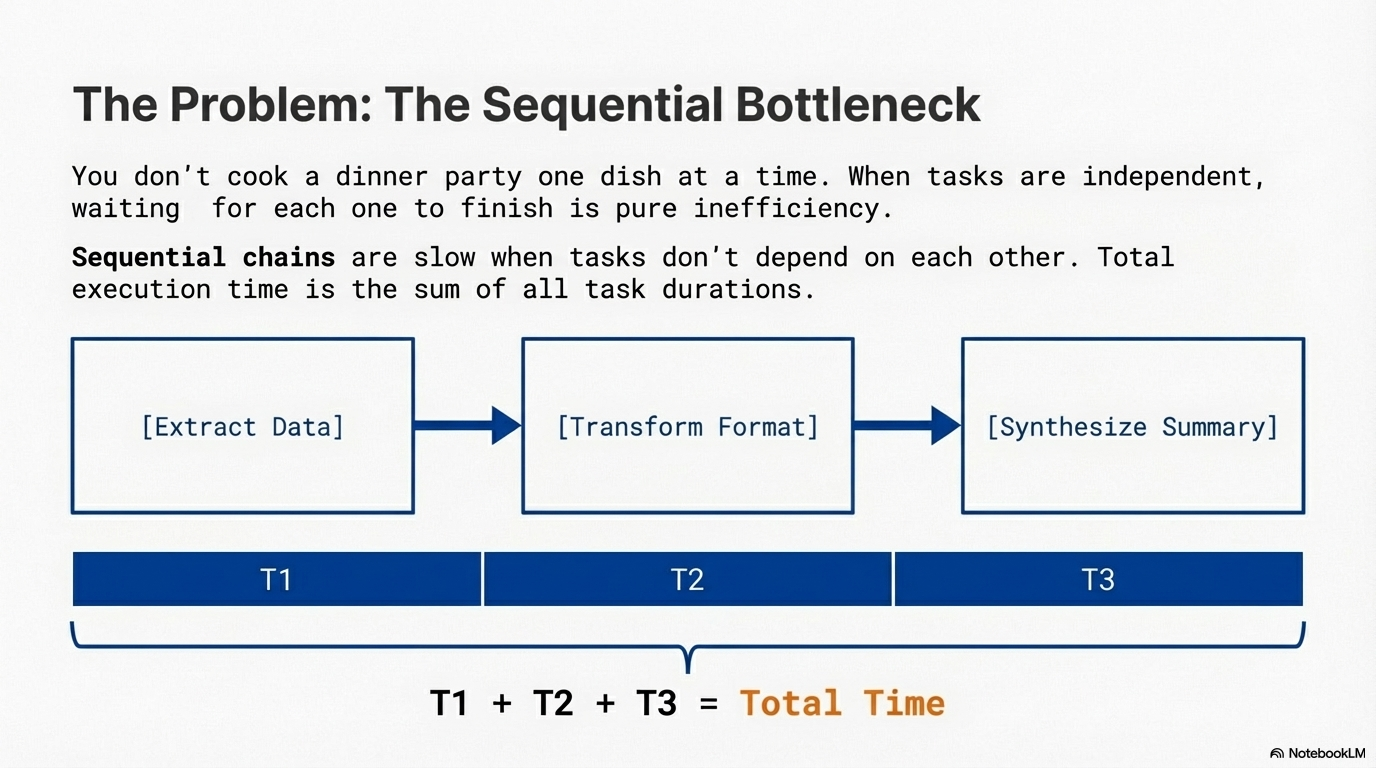
While sequential processing via prompt chaining is foundational and routing enables dynamic decision-making, many complex agentic tasks involve multiple sub-tasks that can be executed simultaneously rather than one after another. Consider an agent designed to research a topic and summarize its findings. A sequential approach might search for Source A, summarize it, then search for Source B, summarize it, and finally synthesize. This sequential execution means total execution time equals the sum of all task durations, leading to inefficiency and poor responsiveness, especially when dealing with external services (like APIs or databases) that have latency.
Solution¶
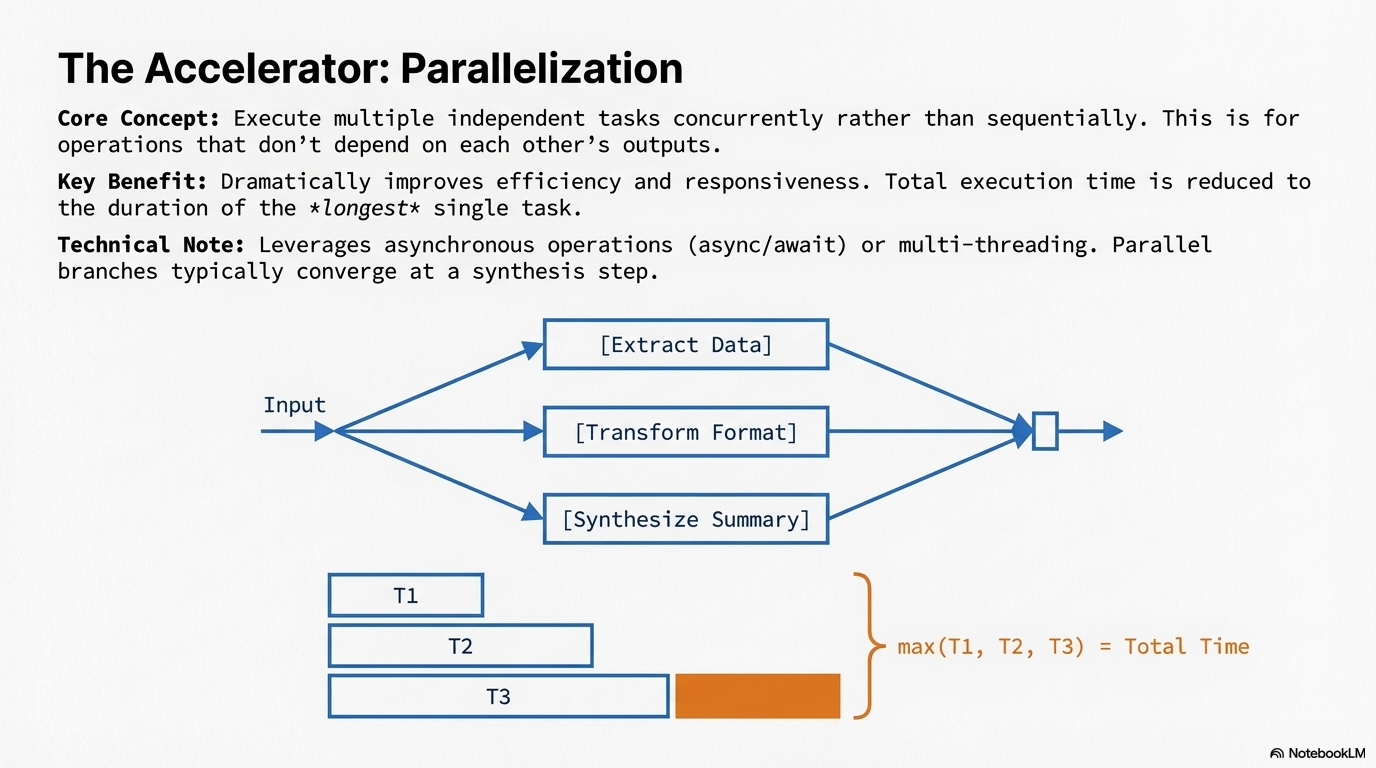
Parallelization is a pattern for executing multiple independent tasks concurrently rather than sequentially, significantly reducing overall execution time for complex workflows. Instead of waiting for one task to complete before starting the next, independent tasks run simultaneously, reducing total execution time from the sum of all task durations to approximately the duration of the longest task. The core idea is to identify parts of the workflow that do not depend on the output of other parts and execute them in parallel.
A parallel approach could search for both sources simultaneously, then summarize both simultaneously, before synthesizing the final answer. Parallelization involves executing multiple components, such as LLM calls, tool usages, or even entire sub-agents, concurrently. This pattern is particularly effective when dealing with external services that have latency, as you can issue multiple requests concurrently. Modern agentic frameworks are designed with asynchronous operations in mind, allowing you to easily define steps that can run in parallel, dramatically improving efficiency and responsiveness of agentic systems.
Key Concepts¶
- Concurrent Execution: Multiple independent tasks run simultaneously rather than sequentially, reducing total execution time.
- Independence Requirement: Tasks must be independent—they cannot depend on each other's outputs to run in parallel.
- Asynchronous Operations: Parallelization leverages async/await patterns or multi-threading to manage concurrent execution.
- Convergence Points: Parallel branches typically converge at a synthesis or aggregation step that combines their results.
How It Works¶
Parallelization works by identifying independent tasks in a workflow and executing them concurrently. The process typically involves: (1) identifying tasks that can run in parallel (no dependencies between them), (2) initiating all independent tasks simultaneously, (3) waiting for all tasks to complete, and (4) aggregating or synthesizing the results at a convergence point. Frameworks provide different mechanisms for this. LangChain uses RunnableParallel to bundle multiple runnables that execute concurrently. LangGraph allows defining multiple nodes that can be executed from a single state transition, enabling parallel branches. Google ADK provides ParallelAgent and SequentialAgent constructs, where a ParallelAgent runs multiple sub-agents concurrently and stores their results in shared state for later synthesis.
When to Use This Pattern¶
✅ Use this pattern when:¶
- Multiple independent lookups: You need to gather information from multiple sources (APIs, databases, search engines) that don't depend on each other.
- Batch processing: You're processing multiple independent items (documents, queries, data points) that can be handled simultaneously.
- Multi-modal processing: You're analyzing different aspects or modalities of the same input concurrently (text sentiment + image analysis).
- Validation checks: You're performing multiple independent validation or verification steps that can run in parallel.
- Content generation: You're generating multiple independent components (headlines, body text, images) that will be combined later.
❌ Avoid this pattern when:¶
- Tasks have dependencies: If one task requires the output of another, they must run sequentially.
- Resource constraints: If you're limited by API rate limits, memory, or computational resources that can't handle concurrent execution.
- Simple workflows: If your workflow has only one or two steps, the overhead of parallelization may not be worth it.
- Synchronization complexity: If managing concurrent execution and result aggregation adds more complexity than benefit.
Decision Guidelines¶
Use parallelization when the time savings from concurrent execution outweigh the added complexity. Consider: the number of independent tasks (more tasks = more benefit), the latency of each task (higher latency = more time saved), and the framework's support for concurrent execution. Be aware that parallelization increases complexity in debugging, error handling, and logging. Also consider cost implications—running multiple LLM calls in parallel increases token usage, though it may reduce total wall-clock time.
Practical Applications & Use Cases¶
Parallelization is essential for optimizing agent performance across various applications where multiple independent operations can be executed simultaneously.
- Information Gathering: Collect data from multiple sources (news, APIs, databases) concurrently to build comprehensive views faster.
- Data Processing: Run multiple analysis techniques (sentiment, keywords, categorization) simultaneously on different data segments.
- Multi-API Interaction: Call multiple independent APIs (flights, hotels, events) concurrently to assemble complete information sets.
- Content Generation: Generate different components (subject lines, body text, images) in parallel for later assembly.
- Validation: Perform multiple independent checks (format, database, content filters) concurrently for faster feedback.
Implementation¶
Prerequisites:
Basic Example
import asyncio
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# Define independent chains
summarize_chain = (
ChatPromptTemplate.from_template("Summarize: {topic}")
| llm
| StrOutputParser()
)
questions_chain = (
ChatPromptTemplate.from_template("Generate 3 questions about: {topic}")
| llm
| StrOutputParser()
)
terms_chain = (
ChatPromptTemplate.from_template("List key terms from: {topic}")
| llm
| StrOutputParser()
)
# Execute in parallel
parallel_chain = RunnableParallel({
"summary": summarize_chain,
"questions": questions_chain,
"key_terms": terms_chain,
"topic": RunnablePassthrough()
})
# Run
result = parallel_chain.invoke("artificial intelligence")
print(result)
Explanation: This example demonstrates parallel execution using LangChain's RunnableParallel. Three independent chains (summarize, questions, terms) execute concurrently on the same input topic. The results are collected in a dictionary, with all three operations completing in approximately the time of the slowest one, rather than the sum of all three.
Advanced Example
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableParallel
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
def process_topic(topic: str):
chain = RunnableParallel({
"summary": ChatPromptTemplate.from_template("Summarize: {topic}") | llm | StrOutputParser(),
"analysis": ChatPromptTemplate.from_template("Analyze: {topic}") | llm | StrOutputParser(),
})
return chain.invoke({"topic": topic})
result = process_topic("artificial intelligence")
print(result)
Explanation: This advanced example processes multiple topics in parallel, each with multiple sub-tasks. It includes error handling using asyncio.gather with return_exceptions, allowing the workflow to continue even if some tasks fail. This demonstrates production-ready parallelization with robust error management.
Framework-Specific Examples¶
Langgraph
from langgraph.graph import StateGraph, END
from typing import TypedDict
class ParallelState(TypedDict):
input: str
result_a: str
result_b: str
def task_a(state: ParallelState) -> ParallelState:
return {**state, "result_a": f"Processed A: {state['input']}"}
def task_b(state: ParallelState) -> ParallelState:
return {**state, "result_b": f"Processed B: {state['input']}"}
graph = StateGraph(ParallelState)
graph.add_node("task_a", task_a)
graph.add_node("task_b", task_b)
graph.set_entry_point("task_a")
graph.add_edge("task_a", "task_b")
graph.add_edge("task_b", END)
result = graph.invoke({"input": "test", "result_a": "", "result_b": ""})
print(result)
Google ADK
from google.adk.agents import LlmAgent, ParallelAgent, SequentialAgent
# Define sub-agents that run in parallel
researcher_1 = LlmAgent(
name="Researcher1",
model="gemini-2.0-flash",
instruction="Research topic A",
output_key="result_a"
)
researcher_2 = LlmAgent(
name="Researcher2",
model="gemini-2.0-flash",
instruction="Research topic B",
output_key="result_b"
)
# Parallel execution
parallel_agent = ParallelAgent(
name="ParallelResearch",
sub_agents=[researcher_1, researcher_2]
)
# Synthesis agent runs after parallel completion
synthesis_agent = LlmAgent(
name="Synthesis",
model="gemini-2.0-flash",
instruction="Combine {result_a} and {result_b}"
)
# Sequential orchestration
main_agent = SequentialAgent(
name="Main",
sub_agents=[parallel_agent, synthesis_agent]
)
Key Takeaways¶
- Core Concept: Parallelization executes independent tasks concurrently to reduce total execution time from sum to maximum.
- Best Practice: Identify truly independent tasks—those with no data dependencies—before parallelizing.
- Common Pitfall: Parallelizing dependent tasks leads to errors; ensure tasks are truly independent.
- Performance Note: Parallelization reduces latency but increases complexity and may increase total token costs (though reduces wall-clock time).
Related Patterns¶
This pattern works well with:
- Prompt Chaining - Parallel tasks often feed into sequential synthesis steps
- Routing - Different routes can execute in parallel when independent
- Multi-Agent - Multiple agents can work in parallel on independent sub-tasks
This pattern is often combined with:
- Planning - Plans can identify which tasks can run in parallel
- Reflection - Parallel results can be evaluated and refined
References
- LangChain Expression Language (LCEL) Documentation: https://python.langchain.com/docs/concepts/lcel/
- Google ADK Multi-Agent Systems: https://google.github.io/adk-docs/agents/multi-agents/
- Python asyncio Documentation: https://docs.python.org/3/library/asyncio.html